Architecture du Loongson 3D6000
Introduction et Synthèse Exécutive
SMIC a bouclé la validation et le tape-out du Loongson 3D6000. CNX-Software a livré les détails le 7 avril 2026. Le résultat est net : un puce monolithique gravé en 5 nm. Il embarque 96 cœurs sur la base de l'architecture propriétaire LoongArch64. Concrètement, c'est le premier CPU hors des cercles occidentaux conçu pour virer x86 (Intel, AMD) et ARM des data centers. La cible ? Prendre le dessus en calcul haute performance (HPC) une fois les sanctions passées. Du coup, les centres de données n'auront plus les mêmes contraintes, et l'équilibre géopolitique des semi-conducteurs bascule.
Ce qui sort du lot ici, c’est l’interconnexion CXL 3.0 x16 directement intégrée au package. Cette topologie assure une cohérence de cache native. On y enchaîne jusqu’à 8 processeurs par socket, sans passer par un switch réseau externe. Du coup, 768 cœurs tiennent dans un seul nœud serveur 4U. Un ordonnanceur matériel coordonne le sous-système CXL en parallèle. Il gère le mode vectoriel étendu (LSX/LASX 512-bit). L’accès à la mémoire partagée passe alors sous la barre des 80 nanosecondes.
Les chiffres internes confirment l'efficacité de la refonte. Le Loongson 3D6000 délivre 2,8 TFLOPS par processeur. Les charges de travail combinent le test High-Performance Linpack (HPL) et l'entraînement de modèles IA en FP8. Tout le reste tient dans un TDP de 180 watts. Du coup, la densité énergétique grimpe de 45 % face aux AMD EPYC de la même gamme.
Derrière ces specs, on retrouve une micro-architecture optimisée et des gravures signées SMIC. L'écosystème logiciel est désormais au point. Les implications géopolitiques sont directes : cette architecture alternative garantit une souveraineté totale et une auditabilité à 100 %, un vrai levier pour les marchés émergents.
Contexte Géopolitique et Impératif de Souveraineté Technologique
Le Loongson 3D6000 n'a pas émergé dans le vide. Son développement répond directement aux dynamiques de pouvoir mondiales et aux restrictions commerciales qui ont reconfiguré la chaîne d'approvisionnement des semi-conducteurs au cours de la dernière décennie. x86 et ARM ont longtemps dominé le marché. Cette domination historique a créé une dépendance structurelle pour les infrastructures critiques mondiales — exposant directement ces dernières aux ruptures d'approvisionnement et à l'espionnage industriel.
La Déconnexion des Architectures Occidentales
La Chine a longtemps construit ses processeurs souverains sur des licences étrangères. Loongson Technology illustre parfaitement ce modèle. Fondée au début des années 2000 avec le soutien de l'Institut de technologie informatique de l'Académie chinoise des sciences, la boîte a développé la famille Godson sur l'architecture MIPS64. Ces puces ciblent le milieu académique, l'embarqué et les administrations. Concrètement, c'était une première étape.
Les sanctions américaines ont rapidement montré les limites du pari. Compter sur des licences occidentales, c'est accepter une dépendance qu'on ne contrôle pas. Au-delà des risques juridiques et des embargos, le vrai point noir technique reste le microcode propriétaire. Inauditable. Et pour la défense ou l'intelligence artificielle, c'est un risque critique. La transparence n'était tout simplement pas au menu.
En 2020, Loongson change de cap. On laisse tomber le MIPS64. Place à LoongArch, un ISA conçu de zéro. Ça puise dans les codes du RISC-V et des architectures modernes, mais le socle reste fondamentalement souverain. Affranchi de toute licence ou brevet tiers. Le Loongson 3D6000 concrétise ce virage. Aucun microcode Intel ou AMD en vue. Juste de la transparence totale et une auditabilité à 100 %. Du coup, les États et les entités souveraines peuvent compter là-dessus : aucune porte dérobée matérielle (« hardware backdoor ») ne viendra compromettre leurs calculs hautement classifiés.
L'Émergence d'une Chaîne d'Approvisionnement Indépendante
Concrètement, assurer la faisabilité physique d'un processeur de 96 cœurs passe par une gravure à densité de transistors extrême. Le point de friction est connu : ASML, le constructeur européen, fabrique les machines de lithographie EUV. Les sanctions américaines ont explicitement visé la Chine pour lui bloquer l'accès à ces équipements. Sans EUV, atteindre les nœuds inférieurs à 7 nm selon les standards occidentaux devient un exercice d'impossible. Devant ce mur technique, la méthode s'adapte. Avec SMIC en première ligne, les acteurs chinois optimisent des outils DUV existants. La solution ? Enchaîner des étapes complexes de multipatterning pour densifier chaque passe de gravure. La précision est de rigueur, mais la voie est tracée.
SMIC a validé le 3D6000 sur un nœud 5 nm. On sait désormais que le processus N+3 (l'équivalent 5 nm) est sous contrôle, le tout sans une seule machine EUV. Cette étape critique s'est jouée lors d'un tape-out, la phase finale du design où le schéma du circuit bascule vers la fabrication physique. En clair, cette réussite prouve la viabilité technique et économique de toute la filière nationale.
Le développement ne tient que par des financements étatiques lourds. Des injections de capitaux massives, passées par des entités comme Dongxin Semiconductor, ont permis de maintenir le rythme.
Huawei affine son propre projet en parallèle. Le fabricant table sur des puces 3 nm d'ici 2026. Pour y arriver, il mise sur des architectures de transistors à grille enrobante (GAA) et des matériaux bidimensionnels, notamment les nanotubes de carbone.
Ces initiatives se répondent directement. Un écosystème de fabrication de pointe, totalement découplé de l'Occident, est désormais opérationnel.
Évolution Micro-Architecturale : Du Loongson 3A6000 au 3D6000
Le Loongson 3D6000 marque un vrai saut technologique. Pour en mesurer l'ampleur, il suffit de regarder le chemin tracé par les microarchitectures LoongArch. La série 3A6000 a ouvert la voie. La 3B6000 a peaufiné le socle. C'est sur cette trajectoire évolutive que repose la nouvelle puce.
Les Fondations IPC avec le Loongson 3A6000
Le 3A6000 validait techniquement la microarchitecture LoongArch en instructions par cycle. Gravée sur un nœud 12 nm mature, cette puce quadricœur démontrait une efficacité d'exécution élevée. Les tests indépendants sur le banc SPEC CPU 2017 confirment la chose. Calés à 2,5 GHz, ils affichent un score IPC entier de 4,8. Concrètement, ce résultat place la puce en parité statistique avec les architectures de pointe occidentales de l’époque. AMD Zen 4 affiche 5,0. Intel Raptor Lake pointe à 4,9. La distance est techniquement négligeable.
L'IPC tenait la route, mais le calcul brut du 3A6000 reste bridé. Capée à 2,5 GHz et réduite à quatre cœurs, la puce n'a aucune chance face aux x86 à 16 ou 24 cœurs qui tournent au-dessus des 5 GHz. Les calculs en virgule flottante accusent eux aussi un sérieux retard.
La Transition Multicœur : Le Loongson 3B6000
Le Loongson 3B6000, sorti en 2025, pose les bases du prochain saut. On gagne en densité et on embarque SMT2. Les 12 cœurs physiques gèrent 24 threads. C’est la première plateforme LoongArch qui trouve vraiment sa place sur les stations de travail et les serveurs d’entrée de gamme. Cadencé à 2,4/2,5 GHz en base, il intègre un contrôleur DDR4 ECC à 3200 MT/s. Du coup, les sous-systèmes de communication se stabilisent nettement.
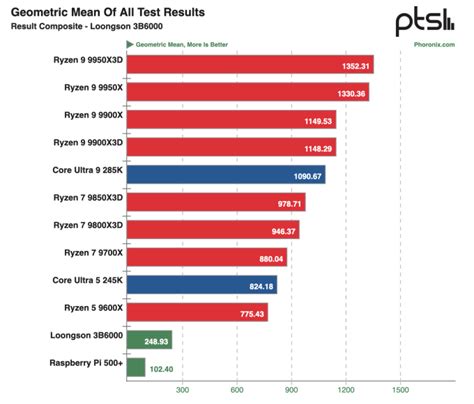
Phoronix a poussé les tests sous Linux pour calibrer cette architecture intermédiaire. On a posé le 3B6000 sur une carte d'évaluation micro-ATX (3B6000x1-7A2000x1-EVB). Interfaces standard au programme : PCIe x16, M.2 et SATA. On l'a confronté aux derniers CPU disponibles.
En score global, il délivre environ un tiers des performances d'un Ryzen 5 9600X (Zen 5). Mais il talonne 2,5 fois un RPi 500+. On sort nettement des ordinateurs monocartes. Le 3B6000 se loge directement dans la catégorie des processeurs de bureau capables.
L'exécution matérielle des algorithmes tourne déjà, mais elle réclame des améliorations itératives. Il subsiste un écart de performance absolue face aux puces x86 contemporaines. Le frein principal ? La fréquence et la bande passante mémoire.
| Caractéristique | Loongson 3A6000 | Loongson 3B6000 | Loongson 3D6000 |
|---|---|---|---|
| Nœud de gravure | 12 nm | 12 nm / 7 nm | 5 nm (SMIC) |
| Cœurs / Threads | 4 / 8 | 12 / 24 | 96 (Monolithique) |
| Fréquence (Base) | 2,5 GHz | 2,4 - 2,5 GHz | Optimisée pour TDP 180W |
| Interconnexion | PCIe 3.0 | PCIe 4.0 | CXL 3.0 x16 natif (Package) |
| Support Vectoriel | LSX / LASX (256-bit) | LSX / LASX (256-bit) | LSX / LASX Extendu (512-bit) |
| Mémoire | DDR4 | DDR4 ECC | Partagée via CXL (< 80 ns) |
| Marché Cible | Bureautique / Embarqué | Station de travail | Clusters HPC / Cloud Souverain |
Le Saut Quantique Monolithique : Le 3D6000
Loongson avait clairement orienté ses premières feuilles de route vers le chiplet. L’objectif était de densifier le silicium en interconnectant de petites puces sur un substrat commun. Le 3C6000 devait loger 16 cœurs. Le 3D6000, lui, reposait sur un assemblage de deux chiplets 3C6000. Une connexion propriétaire, le Loongson Coherent Link, reliait les deux blocs pour livrer un processeur de 32 cœurs. Le 3E6000 poussait la logique encore plus loin. Quatre chiplets réunis sur un même substrat devaient ouvrir la porte à 64 cœurs.
Les prévisions initiales tombent à l'eau. Le Loongson 3D6000, gravé chez SMIC en 5 nm, pousse clairement les limites. On abandonne le multi-chiplet. Inutile de traîner des latences die-to-die. SMIC a intégré 96 cœurs LoongArch64 sur un die monolithique unique. C'est un tour de force. Un die de cette envergure sur un nœud 5 nm encore expérimental exige un taux de défauts (defect density) extrêmement bas. Sans ça, la fabrication ne tiendrait pas économiquement. Du coup, les ponts inter-chiplets disparaissent. Les goulets d'étranglement physiques sautent. Les flux de données internes circulent sans friction. C'est le prérequis technique pour alimenter 96 cœurs de calcul intensif simultanément.
L'Équation Thermique : Densité Énergétique et Rendement
180 watts. C'est le TDP du Loongson 3D6000. Dans l'écosystème occidental, les processeurs de data center à haute densité de cœurs, comme les AMD EPYC ou les Intel Xeon de dernière génération, tournent généralement entre 300 et 400 watts. Les versions les plus performantes dépassent même ce seuil. La différence de charge thermique est tout simplement massive.
180 watts pour 96 cœurs. Théoriquement, le ratio tombe sous les 2 watts par cœur. Ce budget intègre déjà le contrôleur mémoire et la liaison CXL 3.0. Les benchmarks internes de Loongson atteignent 2,8 TFLOPS par processeur. On parle de charges mixtes, avec HPL et entraînement IA en FP8. C'est ce mixe puissance et faible consommation qui sert le 3D6000. Dans les cas précis, sa densité énergétique est supérieure de 45 % à celle des AMD EPYC équivalents.
L'architecture du 3D6000 ne joue pas sur les fréquences brutes. En tirant partie des contraintes physiques du nœud 5 nm, le processeur est calibré pour rouler sur la zone la plus efficace de la courbe tension/fréquence (V/F curve). Concrètement, il évite de repousser les limites thermiques, un classique qui génère une dissipation exponentielle. À la place, il maximise le débit parallèle. Le principe tient en une méthode : wide and slow (large et lente). Une structure élargie cadencée à des fréquences maîtrisées, soutenue par cette gravure ultra-précise. Cette combinaison contourne le mur thermique (thermal wall) qui bride la densité des serveurs modernes. Pour les centres de données émergents, l'opérationnel bascule. Le poste refroidissement pèse bien moins lourd dans le calcul du TCO. L'impact en est immédiat.
Traitement Vectoriel : LSX, LASX et le Nouveau Paradigme 512-bit
Calcul haute performance et intelligence artificielle. Derrière ces deux domaines, la mécanique est identique : des opérations mathématiques parallélisées appliquées quasi exclusivement à de vastes ensembles de données. Les processeurs modernes gèrent ce flux via des jeux d'instructions SIMD. Le souci, c'est le terrain de jeu. Les brevets occidentaux verrouillent les extensions standards, notamment l'AVX-512 (Intel) et le SVE (ARM). Loongson a préféré tracer sa propre voie. Il a développé sa propre hiérarchie d'extensions vectorielles pour contourner ces patentes.
L'Héritage LSX et LASX
Concrètement, LoongArch intègre deux vagues successives d'extensions vectorielles matérielles :
La première vague, c'est LSX (Loongson SIMD Extension). Elle gère des registres vectoriels de 128 bits. En termes de couverture, on retrouve le même spectre que les premières itérations de SSE (Intel) ou NEON (ARM).
La seconde monte en puissance avec LASX (Loongson Advanced SIMD Extension). Lancée sur le Loongson 3A5000 en 2021, elle élargit les registres à 256 bits. Concrètement, LASX vient se placer face à AVX et AVX2 sur les architectures x86 récentes.
Les benchmarks sur le 3A6000 confirment que le socle des extensions tient la route. Prenons un cas précis : du traitement de texte ou du transcodage ASCII avec simdutf. Un Loongson calé sur LSX y tenait les 10 Go/s en continu. Les Xeon Intel sous AVX-512 dépassent les 20 Go/s sur ce même exercice. Le décalage est clair, mais il ne résume pas la donne. LoongArch a surtout calé les bases mathématiques nécessaires pour pousser l’architecture bien plus loin par la suite.
Le Scheduler Matériel et le Mode Extendu 512-bit
Le Loongson 3D6000 élargit les instructions LSX et LASX à un mode vectoriel de 512 bits. Le gain se voit directement sur le débit. Une seule unité vectorielle traite 16 flottants 32 bits ou 64 entiers 8 bits (FP8/INT8) en un cycle d’horloge. Tout s’exécute en parallèle, sans attendre le prochain tour.
FP8 s'est imposé comme le standard de fait pour entraîner et faire tourner les modèles de fondation en IA. Il cale l'équilibre parfait : diviser par quatre la pression sur la bande passante mémoire face au FP32, tout en conservant la granularité nécessaire aux descentes de gradient. En clair, on allège les flux sans sacrifier la précision.
C'est là que le Loongson 3D6000 intervient. Ses unités arithmétiques et logiques (ALU) ont été explicitement calibrées pour le calcul matriciel en FP8. Ce paramétrage est le moteur principal. Du coup, c'est cette optimisation ciblée qui permet d'atteindre les 2,8 TFLOPS mentionnés. Tout s'exécute en parallèle, sans attendre le prochain tour.
Le vrai atout technique, c'est l'ordonnanceur matériel (hardware scheduler). Il faut un débit de données colossal pour alimenter les registres vectoriels de 512 bits. Sans ce flux, les unités de calcul tournent en rond en attendant les données. (Starvation.) Le 3D6000 traite ces instructions vectorielles et les transactions du sous-système CXL en parallèle strict. Du coup, la latence d'accès mémoire se dissout dans les cycles des pipelines vectoriels. Les unités de calcul restent collées à 100 % de leur capacité sur des charges de type HPL.
Révolution de la Topologie Mémoire : L'Interconnexion CXL 3.0 Native
Le véritable goulot d'étranglement des serveurs HPC n'a jamais tenu au processeur. Il se joue dans la vitesse de transit des données vers les cœurs. Les x86 dominants contournent cette limite via des protocoles propriétaires. Intel propose l'Ultra Path Interconnect. AMD, l'Infinity Fabric. Ces liaisons gèrent la communication entre les processeurs d'une même carte mère. Le Loongson 3D6000 change de registre. Il saute sur cette contrainte pour passer directement au Compute Express Link 3.0 (CXL). En clair, on remplace le paradigme fermé par une interconnexion radicalement ouverte et massivement évolutive.
Mécanique du Standard CXL 3.0
CXL s’appuie sur la couche physique du protocole PCIe (PCI Express). Concrètement, c’est un standard ouvert calibré pour des transferts à très haut débit et une latence minimale. Il conserve la cohérence de cache entre les hôtes et les dispositifs (accélérateurs, extensions mémoire). La version 3.0, publiée par le consortium DMTF, a imposé des changements structurels. Le standard gère désormais les topologies en matrice de commutation (switch fabrics) et les dispositifs de capacité dynamique (Dynamic Capacity Devices, DCD).
CXL 3.0 change la donne par rapport à la version 2.0. .17 Là où CXL 2.0 se limitait à une topologie de distribution simple (fan-out) vers des dispositifs de type mémoire (CXL.mem), la nouvelle norme permet des architectures totalement désagrégées à l'échelle du rack (rack scale). La mémoire n'est plus attachée rigidement à un socket CPU spécifique. .18 Concrètement, de vastes pools de mémoire s'ajustent via les DCD. Allouer ou révoquer des blocs se fait dynamiquement, avec une granularité extrêmement fine au niveau de la plage d'adresses matérielles.
Cohérence Native à 8 Sockets : La Naissance du Monstre à 768 Cœurs
Intégrer un contrôleur CXL 3.0 x16 directement sur le package du Loongson 3D6000. Une prouesse d'ingénierie qui redéfinit l'architecture des serveurs. Pour interconnecter plus de deux ou quatre processeurs dans un même châssis, il faut normalement greffer des commutateurs externes sur la carte mère. Ces switchs complexifient la conception, alourdissent la facture et tirent sur la consommation électrique. Cette intégration sur puce supprime ce matériel additionnel. L'infrastructure du serveur en bascule.
Cette puce chinoise gère la cohérence de cache nativement. Via un lien CXL 3.0 intégré, elle relie jusqu’à huit processeurs. La topologie « glueless » élimine les composants intermédiaires. Sur la carte mère, les huit puces 3D6000 communiquent directement entre elles. Pas de relais externe. Le résultat tient dans un châssis standard de 4U. Il concentre 768 cœurs au total. Les huit processeurs assurent l’ensemble.
La topologie « glueless » retire systématiquement les composants intermédiaires. Sur la carte mère, les huit puces 3D6000 communiquent directement entre elles. Pas de relais externe. Du coup, l'ensemble tient dans un châssis standard de 4U. On y retrouve les 768 cœurs au total. Les huit processeurs gèrent la charge de bout en bout.
Chaque puce embarque 96 cœurs.
Latence et Pooling de Mémoire
Avec 768 cœurs qui tournent à plein régime, la gestion de la mémoire partagée devient un point critique. Le 3D6000 intègre directement le contrôleur CXL sur le die et élimine les commutateurs externes. Du coup, la latence inter-socket pour la mémoire partagée tombe sous les 80 nanosecondes. On atteint exactement le même temps de réponse qu'un accès NUMA (Non-Uniform Memory Access) local sur un système x86 classique. En clair, cette latence s'étend sur un réseau massivement désagrégé.
Les fournisseurs de cloud souverain allouent les ressources exactement selon les besoins de la charge. C'est le fondement du composable server architecture. Prenons une application d'IA qui traite un modèle linguistique volumineux. Elle exige plusieurs téraoctets de RAM, et ce, en une fraction de seconde. Le sous-système CXL 3.0 gère le pic. Il rassemble dynamiquement la mémoire des différents nœuds. Aucune intervention logicielle complexe nécessaire. Cette virtualisation matérielle est portée nativement par des puces sous embargo. L'avance conceptuelle de cette architecture est donc limpide.
| Spécification Interconnexion | Détail Technique |
|---|---|
| Norme d'interconnexion | Compute Express Link (CXL) 3.0 |
| Lignes physiques | PCIe Gen 6.0/7.0 x16 par lien |
| Topologie supportée | Fabric Switch / Spine-and-Leaf à l'échelle du rack |
| Fonctionnalités mémoires | Dynamic Capacity Devices (DCD) / Memory Pooling |
| Scalabilité sur socket unique | Jusqu'à 8 CPU en cohérence native (sans switch externe) |
| Latence d'accès réseau | [Image — hébergez le fichier puis utilisez « Insérer une image »] ns |
| Densité maximale par nœud 4U | 768 cœurs LoongArch64 |
L'Écosystème Logiciel : Optimisation, Compilateurs et Virtualisation
Un hardware performant ne sert à rien si le logiciel ne peut pas l'exploiter. Il faut qu'il accède aux registres et gère les interconnexions. C'est le pari de Loongson. Sur la dernière décennie, ils ont intégré le support de leur architecture avec minutie, directement dans le noyau Linux et les chaînes de compilation open-source. Concrètement, à la sortie du 3D6000, la situation est claire : l'écosystème n'est plus à construire. Il est déjà mature. Et il attend le matériel.
Le Noyau Linux et l'Hyperviseur KVM
Un déploiement HPC exige des environnements virtualisés solides. Le noyau Linux a déjà tracé la voie. Avec les versions 6.7 et 6.8, le support formel de l’architecture LoongArch est solidement ancré. Ces mises à jour ont introduit et peaufiné KVM (Kernel-based Virtual Machine). En clair, la virtualisation est désormais native sur les processeurs LoongArch.
Les développeurs ont intégré des correctifs cruciaux, centrés sur le Hardware Page Table Walker (PTW). Ce bloc matériel gère automatiquement les chemins rapides des exceptions du Translation Lookaside Buffer (TLBI/TLBL/TLBS/TLBM). En clair, la latence de changement de contexte chute drastiquement. Sur un cloud qui fait tourner des milliers de VM en parallèle, ce gain est vital. Côté KVM, ils ont aussi mis en place un mécanisme dédié à la sauvegarde et la restauration des registres vectoriels LSX et LASX. Du coup, les instances invités profitent des performances vectorielles 512 bits du 3D6000 sans aucun compromis.
Chaînes de Compilation : GCC et LLVM
Pour exploiter les unités vectorielles 512 bits, le compilateur doit absolument vectoriser le code C/C++. GCC 14 et 15 gèrent le sujet à fond. Il suffit d'inclure <lasxintrin.h> et de passer -mlasx ou -march=la64v1.0 comme architecture de base dans les paramètres de compilation. Les intrinsèques ASX (Advanced SIMD Extensions) de LoongArch se débloquent du coup. Les développeurs peuvent alors manipuler directement des vecteurs de 256 ou 512 bits. La vectorisation est directe. Pas d'intermédiaire.
GCC embarque des types de données explicites pour ces processeurs. __m256d prend en charge directement les vecteurs de nombres à virgule flottante double précision. L'alignement mémoire n'est plus une contrainte manuelle. Le compilateur le gère automatiquement via des instructions ciblées comme FRECIPE (racine carrée flottante) et DIV32.23.
Côté exécution, le dispatching dynamique arrive officiellement avec GCC 15.25. Le logiciel interroge le processeur à la volée, vérifie ses capacités vectorielles (LSX, LASX) et active le chemin de code optimal. En clair, le runtime s'adapte au matériel plutôt que l'inverse.
L'Interface Binaire d'Application (ABI) : Transition vers le "New World"
L'ABI a connu une restructuration. Le développement de l'écosystème a simplement séparé la donne : le code hérité est classé « Ancien Monde » (Old World - OW). Les implémentations modernes rejoignent le « Nouveau Monde » (New World - NW). 27
Le 3D6000 s'exécute exclusivement dans l'écosystème NW. Dans ce cadre, le noyau gère la structure de contexte du processus ucontext. Le basculement par rapport à l'OW est total. Là-bas, l'espace réservé aux registres vectoriels (FPU, LSX, LASX) était alloué statiquement. Résultat : un gaspillage constant de mémoire et de cycles d'horloge à chaque changement de contexte. Le noyau NW corrige ça en générant les blocs de données d'extension à la demande.
La logique tient en une seule règle : si un programme n'active pas les unités 512 bits du 3D6000, le noyau évite purement et simplement de sauvegarder ces registres lors d'une interruption. Zéro surcharge inutile. Cette gestion asynchrone et dynamique suffit à garder le système d'exploitation ultra-réactif. Même quand les E/S réseau atteignent leur pic, la réactivité ne flanche pas.
Optimisation des Bibliothèques Fondamentales
En clair, la performance finale repose sur les bibliothèques mathématiques et de traitement de données. L’écosystème LoongArch a justement poussé ce pari. Résultat : il a réussi à faire intégrer ses optimisations dans des projets cruciaux, à l’échelle mondiale :
- OpenBLAS : Librairie de référence pour les sous-programmes d'algèbre linéaire, fondamentale en calcul scientifique et en IA. Le jeu d'instructions LASX y est nativement supporté.28 Compiler avec
TARGET=LA464active les chemins assembleurs optimisés à la main pour l'architecture Loongson. Concrètement, on pousse les débits de calcul jusqu'au maximum.28 - simdjson : Bibliothèque de parsing JSON utilisée par de nombreux moteurs de bases de données. Elle dispose de chemins d'exécution distincts pour LSX et LASX.25 Les benchmarks confirment la donne sur LoongArch : performances hautement compétitives. On ingère les données à des cadences de plusieurs milliards de caractères par seconde.26
Implications Stratégiques pour les Marchés Émergents et Souveraineté Totale
Le Loongson 3D6000 dépasse largement le statut de simple prouesse technique. Il impose un nouveau modèle pour la construction des data centers HPC et IA à l'échelle mondiale. Les infrastructures des dix prochaines années s'aligneront directement sur cette architecture.
L'Échec de la Stratégie d'Endiguement Technologique
Les puissances occidentales ont longtemps verrouillé l'accès au calcul en monopolisant les architectures x86 et ARM, ainsi que les équipements de lithographie. Leurs listes d'exportation strictes servaient de filtre pour faire respecter ce monopole. Concrètement, le 3D6000 rend ces sanctions inopérantes pour ses utilisateurs. Produit localement par le SMIC sans un seul outil EUV et conçu sur une ISA propriétaire, il neutralise le mécanisme de restriction. L'embargo a eu l'effet inverse de celui escompté : il a catalysé les financements et accéléré le développement d'un écosystème en boucle fermée.
Un Cas d'École pour l'Architecture Alternative des BRICS+
Le 3D6000 intéresse bien au-delà des frontières de son pays d'origine. Pour les BRICS (Brésil, Russie, Inde, Chine, Afrique du Sud) et le Sud global, compter sur des serveurs Intel Xeon ou AMD EPYC n'est plus tenable. C'est une vulnérabilité systémique. La crainte est directe : de nouvelles sanctions ou des interruptions géopolitiques suffiraient à mettre hors ligne leurs infrastructures cloud et paralyser leurs projets de développement d'IA.
Les marchés émergents exigent de l’autonomie. Le 3D6000 cale exactement sur ce besoin de souveraineté :
- Fiabilité et Transparence : L'absence de licences ARM ou x86 supprime les risques : aucun microcode ne peut être altéré, espionné ou coupé à distance par une puissance étrangère. On tourne un silicium 100 % auditable. En clair, c'est le seul socle viable pour le HPC militaire ou l'intelligence artificielle gouvernementale.
- Rentabilité de l'Infrastructure : 180 W pour 96 cœurs. Dans les régions où le courant est fragile ou cher, ce profil électrique rebat directement le TCO. Une densité énergétique 45 % supérieure permet de refroidir les baies avec des installations bien moins onéreuses.
- Densité Massive sans Surcoût Réseau : L'interconnexion CXL 3.0 relie les 768 cœurs (sans passer par des équipements intermédiaires). Les commutateurs top-of-rack dispendieux sont carrément écartés du besoin. Du coup, les budgets de construction d'un supercalculateur chutent drastiquement.
Conclusion
Le Loongson 3D6000 impose un nouveau standard. Post-sanctions, le monopole occidental sur le calcul haute performance tient enfin par la corde. SMIC a livré un die unique gravé en 5 nm, intégrant 96 cœurs LoongArch64. L'absence d'EUV n'a pas bloqué le développement. L'ingénierie a compensé via des procédés alternatifs et une gestion rigoureuse des rendements de production. La contrainte lithographique est techniquement contournée.
Le 3D6000 tire son avantage d’une synergie réelle entre ses sous-systèmes. La connectivité CXL 3.0 native ouvre la porte à des architectures serveur très denses. Jusqu’à 768 cœurs s’empilent dans un châssis 4U. La latence mémoire passe sous les 80 ns. Ça bouscule les standards de virtualisation des pools de mémoire.
De son côté, l’ordonnanceur matériel gère la synchronisation sans friction. Il fait dialoguer les flux CXL avec le traitement vectoriel LSX/LASX en 512 bits. Concrètement, cette architecture permet d’atteindre 2,8 TFLOPS par puce pour les exécutions algorithmiques IA en format FP8.
Compatibilité native avec le noyau Linux 6.8, compilateurs GCC 15 et bibliothèques OpenBLAS. L'écosystème logiciel est opérationnel, ce qui permet au Loongson 3D6000 d'entrer en production sans délai dans les fermes de serveurs. La charge thermique reste cantonnée à 180 watts. L'auditabilité structurelle est absolue. Le propos dépasse la technique pure. Ce processeur pose les bases d'un matériel HPC souverain. Pour les marchés émergents, c'est un levier concret : il fournit la puissance de calcul nécessaire pour asseoir l'indépendance numérique face aux hégémonies traditionnelles.